手部姿态估计领域文献阅读笔记分享
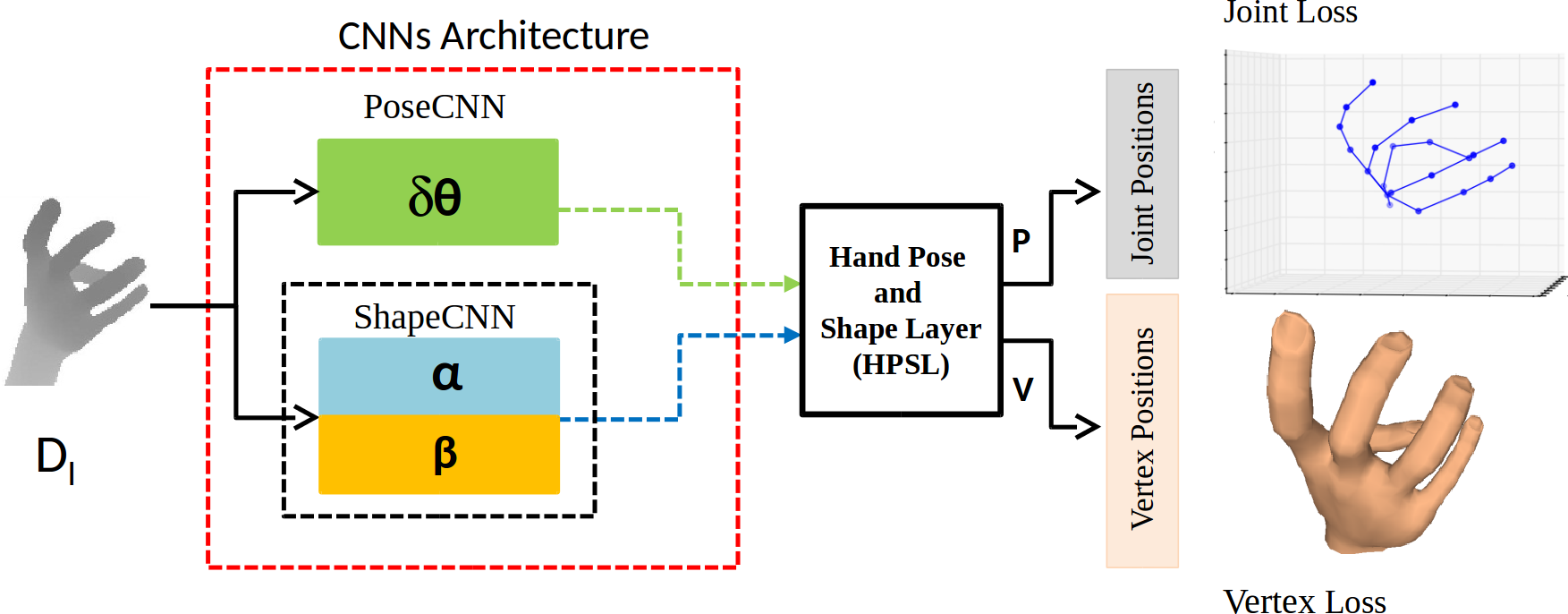
2018 | DeepHPS: End-to-end Estimation of 3D Hand Pose and Shape by Learning from Synthetic Depth
这篇论文提供了合成深度图→Mesh的数据集,它用三个独立的CNN分别预测pose parameter、scale、shape参数相对于标准手势的offset,然后用HPSL层处理得到关节点坐标和手的mesh。关键的HPSL层嵌入了关节点骨骼模型、手模型等,根据offset推测手势。
20arXiv | HandAugment: A Simple Data Augmentation Method for Depth-Based 3D Hand Pose Estimation
two-stage方法,先用net1在官方给的粗粒度手部区域上估计pose,再利用估计出来的 xmin, xmax, ymin, ymax, zmin, zmax(30mm) 截手(截取z轴时除了offset外,因为hand skeleton总是在hand skin前面,为了截取完整手部,需要考虑手指厚度: zmin-zoffset-zthickness(20mm))。这种方法要求有初始的大致的手框,但是对一个包含完整的人的原图也不适用,需要大致定位手的位置;
使用手模型(MANO)合成图片进行数据增广,RealDataset,SyntheticDataset,MixedDataset,NoisedDataset(在给的MANO参数上加上高斯噪声,合成新数据)
该方法的优势主要体现在第二点,只用真实数据集训练在HANDS19数据集上只有16.50mm(我们的ResNet50-AWR是14.89mm),加上增广数据后,该方法从16.50mm→13.66mm;但是在NYU数据集上,该方法的平均误差只有9.02mm(对比我们ResNet18-AWR 7.75mm)。
18ECCV | Occlusion-aware Hand Pose Estimation Using Hierarchical Mixture Density Network
本文针对遮挡问题,提出被遮挡的关节点位置存在多种可能性,而判别模型最后只给出一个确定的结果,这个结果是多种可能性的均值,特别是使用MSE loss,更倾向于平滑输出,会产生物理不存在的手势。因此设计了分层网络结构,先预测关节点的visibility关节点分类(visible,occluded等),再对不同类别设计不同的概率分布(单个/多个高斯blob)。
文章没有给出数据集上整体的平均误差
遮挡问题中被遮挡的关节点位置有多种可能性,预测结果是这些可能性的均值的问题应该存在于任何带加权平均的方案中。
20AAAI | Simple Pose: Rethinking and Improving a Bottom-up Approach for Multi-Person Pose Estimation
基于RGB的多人姿态估计,有几个可以参考的点:第一个是hourglass+multi-scale(SEblock)嵌入空间attention,第二个是改进了focal l2 loss,解决正负样本和easy&hard样本不均衡的问题。这篇论文属于bottom-up类,另一种top-down类是先检测再姿态估计。
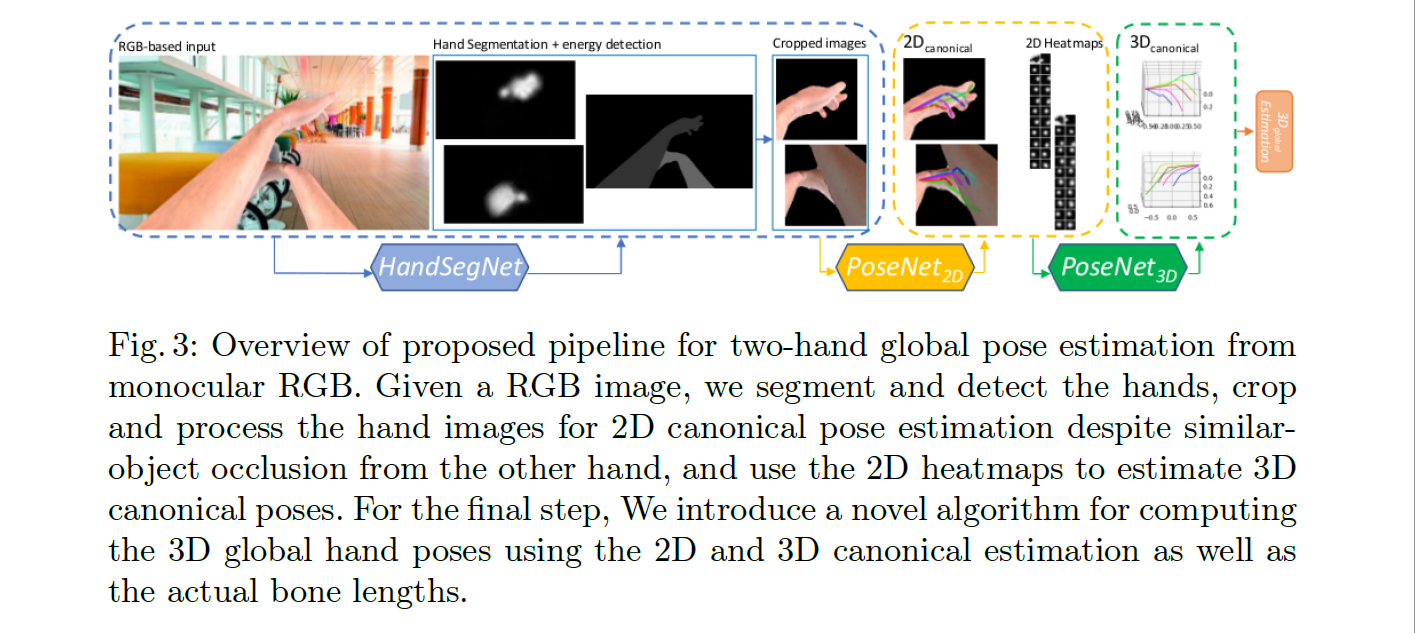
2020 | Two-hand Global 3D Pose Estimation using Monocular RGB
流程是分割→ 2D Pose → 3D Pose(相对坐标)→ 3D Pose(global坐标), 提出了第一视角下的双手合成数据集,一个trick是对分割出的两只手中的辅助手(确定方法未提)的亮度降低0.5。
18ECCV | Estimating 2D Multi-Hand Poses From Single Depth Images
Two-stage 方法:先用Mask RCNN获得初始pose和手的语义分割结果,利用语义分割结果获得pose prior(global constraints),与初始pose(local information)结合得到最终结果。和其他解决方案最大的区别在于它可以同时进行语义分割和关节点检测,并且语义分割结果不是用来截取图像再进行姿态估计,而是用它计算先验知识对前一步的关节点检测结果进行优化,但是只能估计2D pose,而且论文里给出的公式支撑也只适用于各个关节点相互独立的情况,和实际情况不符;利用深度图只进行了2D的姿态估计,似乎用RGB会更贴合,并且解决方案中没提及对于深度图的独特处理,甚至输入都是copy成三通道。
利用单手数据集生成双手数据集,缺少两只手交互的情况,复杂度不够,
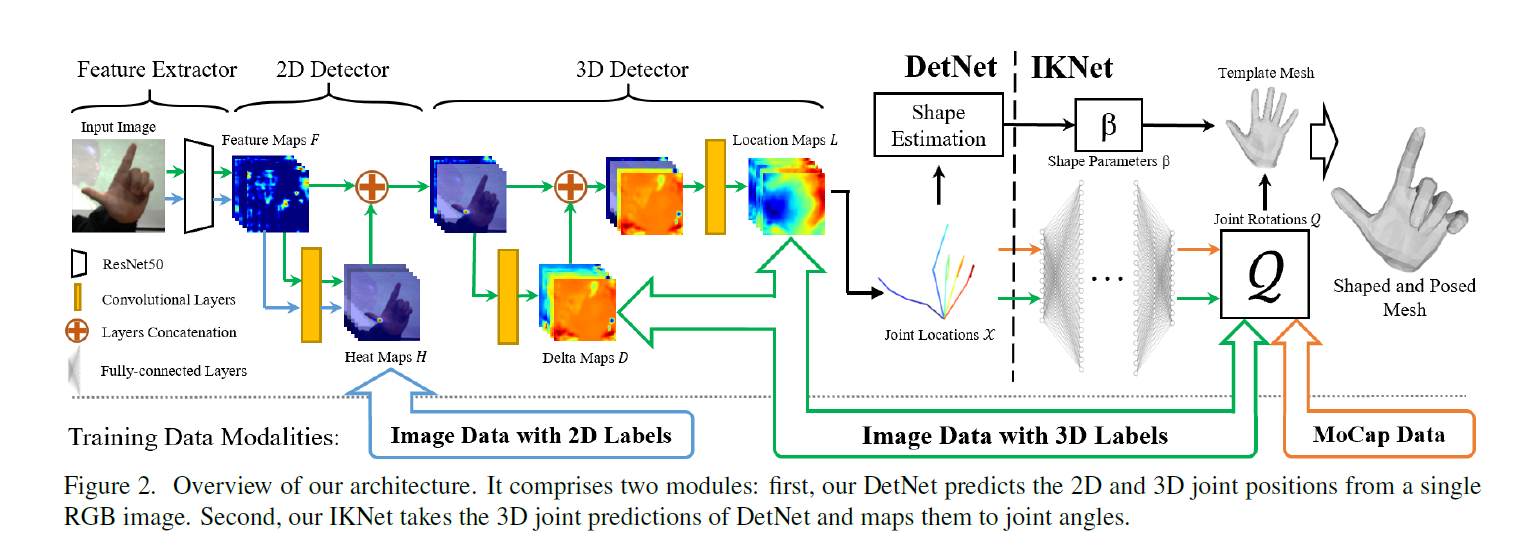
20CVPR | Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
综合使用合成、真实图片、2D/3D标签和MoCap数据,用于预测关节点坐标 (DetNet) 和角度 (IKNet,用MoCap数据做直接监督,关节点坐标作为弱监督),利用角度和形状参数与MANO手模型结合获得手的mesh。数据预处理的normalize方式是-center再除以bone length(center到wrist的距离)。
17ICCV | Learning to estimate 3d hand pose from single rgb images
最早用RGB估计3D Pose的论文之一,本文提出了RHD数据集以及基于RGB的分割+3D姿态估计模型。数据集给出了手的分割mask+21个关节点坐标,模型分为3个子网络:分割网络 (CPM),2D姿态估计网络和3D姿态估计网络。为了解决depth ambiguity的问题,3D姿态估计网络估计的是归一化的相对坐标,两个branch分别预测标准3D Pose和三个坐标轴上的旋转角度,通过标准pose的变换得到最后的结果。

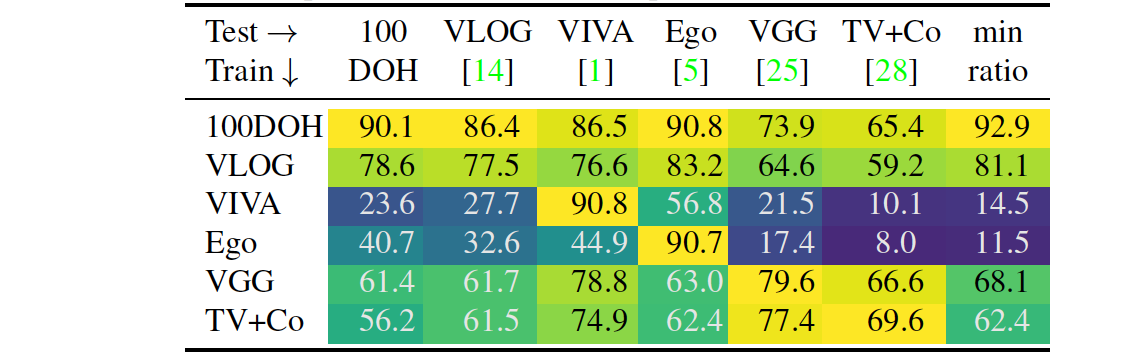
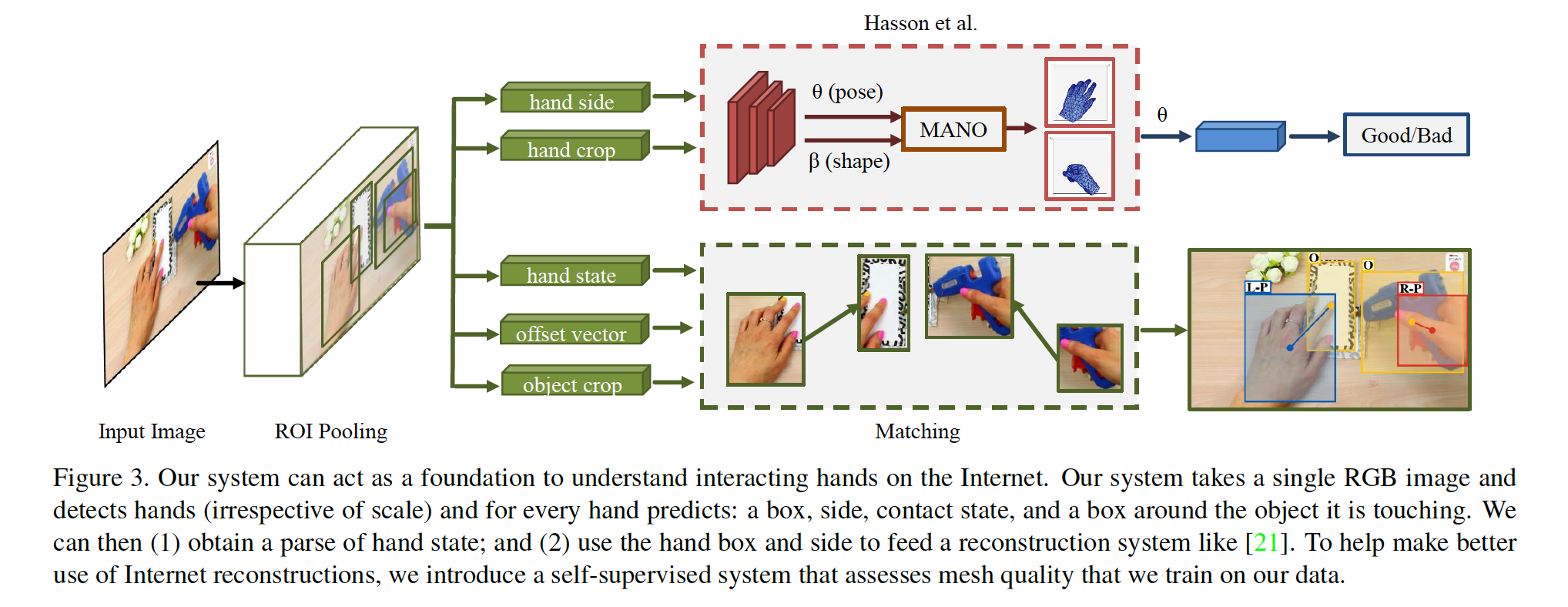
20CVPR | Understanding Human Hands in Contact at Internet Scale
实现日常场景下手的检测,包括手的位置、side (左手、右手)、交互状态 (无、自身、其他人、不可移动物体、可移动物体)、交互物体的位置,其中前两项对后续的手部姿态估计比较重要,并依此提出一个100K的数据集——100DOH,数据集给出的标注信息很丰富,可以用于手与物体交互、in-the-wild单手/多手姿态估计等。在该数据集上训练的detector对于其他数据集的泛化效果比较强。
论文重点在于数据集,方法层面上手的检测用的Faster-RCNN,手的Mesh估计用的MANO手模型,是一个比较完整的系统。
13ICCV | Efficient Hand Pose Estimation from a Single Depth Image
早期的用深度图解决手部姿态估计的文章,基于Hough Forest,CPU上达到12帧,侧重于解决深度图的噪声。将姿态估计分为三个步骤:1)预测手的平面方向和3D位置 (Hough Forest); 2)利用深度特征生成候选Pose (Hough Forest);3)优化得到3D姿态估计结果。论文介绍了深度图中两种noise类型:边界附近的阴影和边界小部分区域缺失 (不平滑)。
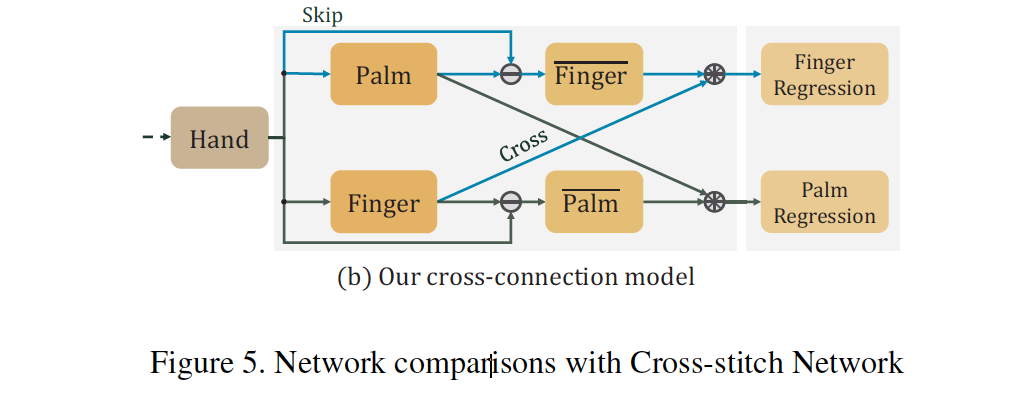
19CVPR | CrossInfoNet: Multi-Task Information Sharing Based Hand Pose Estimation
在关节点回归的pipeline中加入heatmap作为中间监督,避免对heatmap进行不可导的后处理。
提出具有两个branch的网络,分别负责手掌关节点 (对global pose影响大) 和手指关节点 (对local pose影响大) 的坐标回归,再通过下图中的方式,将两个分支中finger和palm的特征分别concat起来,分别回归关节点坐标。这里面的相减操作比较新颖,相比baseline(没有信息交互)有提升,但是没有对比论文里提到的另一种lazy cross-stitch。论文点数不是很高,但是multi-task的组合方式很新颖。
RegionEnsembleNetwork里面也是分为多个sub-tasks,将feature map的不同部分截出来分别处理,最后让FC学习sub-tasks之间的关系。相比之下,这种方法加入了更多设计的元素。