
写在前面:我是今年秋招卷算法的一员,经历了几段实习和秋招(等尘埃落定会分享一下),最大的体验就是刷题重要,但不是最重要的,如果你有足够丰富的论文/竞赛/项目/实习,一般留给编程的时间不多,题目也相对简单,当然也有像微软这种有固定几轮coding的公司,不过也有一些能缓解这种“被人盯着写代码”的压力的面试小技巧。
先贴下LeetCode刷题记录,其中比较经典的比如剑指Offer、TopInterview、前两百题刷了至少两遍,虽然总量不能跟大佬们比,但也有一些小小的心得。
刷题初期 —— 减少抵触,养成习惯
我是研一开始陆陆续续刷题的,当时感觉时间还早,而且我本科不是计算机专业的,刷算法可以说从头开始,所以刚开始的时候非常之煎熬,刷的量也很少,经常一周就刷一两道剑指Offer,也很推荐刚开始的时候先用剑指把大致题目、算法、数据结构做个初步了解,这样后面刷到类似题目的时候抵触情绪会少点。
刷完剑指后我继续刷LeetCode是从TopInterview这个列表刷起的,刚开始不敢挑战自己,只挑easy,最多来几道medium,就这样第一遍还很多看完题目直接看题解的。刚开始刷题为了减少抵触、挫败的情绪,帮助养成刷题的习惯,我是看完题目自己想几分钟就去看题解,自己做出来的也会看一下题解或者评论里有没有什么有意思的写法。有点搞笑的是,刚开始还挺“追求”一行代码的,现在想想属实没必要哈哈哈,实际写工程代码的时候实现功能是一部分,代码的可读性也是一些公司考察的点~
刷题上道 —— 善于总结,便于回顾
我大概刷了两百题后,开始跟LeetCode上的“每日一题”,也是这个阶段开始见到题目会有“似曾相识”的感觉,是之前做过的题目的衍生题,或者方法、代码极为相近。于是我开始对做过的题进行记录。
其实刚开始刷题的时候我就有记录刷过的题(姑且当做虚荣心作祟hhh,达到50、100、200这种跨越数量级的就很有成就感),这也是我引以为傲的一个刷题技巧。在这个表中,我会记录每道题的题目、我的解法、题目数据结构、用到的算法、是否需要重刷(取决于第一次有没有一遍过)、一些奇妙的解法和注意点、刷题日期,最后加的ToDo可以在不断回刷的时候掌握进度。
我比较喜欢的是Notes这一栏,会记录一些自己、他人解法的关键点,后面刷到类似的题目会加个 “Link No.xxx” 字眼,方便在回看的时候顺便对比一下相似题目的不同点与对应的解法。

这里我用的是Notion,用一个Table记录,给每道题加上标签后,可以根据标签选择不同的View,这样在复习的时候能很方便地根据数据结构、算法以及难易程度划分。
在不断刷题的过程中,除了数组、字符串、链表、二叉树这类常见的数据结构,也有并查集、字典树、优先队列这种相对生疏的题目,我的做法是再开一个笔记,记录不熟悉的算法和数据结构(文末附个人笔记),除了记录一些定义、解法,也会附上题目编号方便复习后及时练手。
刷到后面相似题目实在比较多的,也会列在这个笔记里。一般来说这个笔记是我笔试、面试前会大致过一遍的,以免遇到“这道题我隐约记得我做过、清楚地记得我没做出来”这种尴尬又遗憾的情况。
一些面试技巧
在这里先碎碎念一些面试过程中感觉比较重要的点,后面有需要的话等秋招结束专门写一篇(不过像我这种年终总结拖到第二年年中的人说的话难有说服力,暂且立个flag吧hhh)。很多技巧我之前也不知道,是在微软实习的时候,我的mentor在转正的时候帮我找同事模拟面试过程中,面试官一点点跟我讲的,到现在都觉得受益匪浅。
面试考察算法、代码和沟通,其中算法就靠刷题,代码的话会考察可读性、可维护性和corner case,但是其中最重要的,我觉得是沟通。
即使是专门考察coding的面试,也不完全说你一听完题目、没有思路就完了,一道题即使你一点思路都没有,不知道用什么数据结构表示、听不懂面试官的描述、要考虑的东西太多一时不知道从哪儿着手,你都可以、而且很有必要跟面试官反复交流,可以让面试官给一些例子,如果你自己想到一些corner case不知道面试官期望的答案是什么也要问,在一问一答中体现你的思考,及时纠正错误的思路。
写之前先向面试官阐述一下你的思路,并且主动说明算法的时间、空间复杂度,即使是暴力法也没关系,先询问面试官需不需要进行什么优化,一般会让你先写出来,再继续想优化的思路;写代码的过程中务必想清楚再写,不要有大幅度的删改(这点在线下面试、手写代码的时候更为重要),如果感觉代码有点繁琐或者时间来不及了,可以问面试官某些步骤可不可以省略,或者一些逻辑简单但代码繁琐的部分,可以写伪代码或者注释。在面试过程中最好不要有超过5分钟的沉默(奋笔写代码除外),想不出来及时向面试官要线索/要求换个题目。
我的算法笔记
在附笔记之前,很想说的是,别人的笔记说的再天花乱坠都是别人的,我也看过很多刷题模板、笔记,要逼着自己去套别人的模板还是挺难受的,所以不必一定要一板一眼照着来,按自己习惯来就好。如果我的笔记能给你带来一点点启发,帮助你梳理,我会感到非常非常开心和荣幸~
动态规划
- No.62 不同路径
- No.64 最小路径和
- No.174 地下城游戏,逆推有点难想到
二维动态规划
- No.72 编辑距离
- No.97 交错字符串
- No.115 不同的子序列
- 剑指 Offer 60. n个骰子的点数
桶排序
- No.164 最大间距(也可用基数排序)
Rabin-Karp算法 O(n)时间实现子字符串查找 → 散列(数字表示字符串)+哈希**
- No.187 重复的DNA序列
- No.1044 最长重复子串
二分法 —— 边界处理
- No.1885 Count Pairs in Two Arrays
- No.33 搜索旋转排序数组;No.81 搜索旋转排序数组 II → 搜索target值
- No.153 寻找旋转排序数组中的最小值;No.154 寻找旋转排序数组中的最小值 II → 搜索最小值
- No.616 给字符串添加加粗标签
旋转排序数组
- No.33 搜索旋转排序数组;No.81 搜索旋转排序数组 II → 搜索target值
- No.153 寻找旋转排序数组中的最小值;No.154 寻找旋转排序数组中的最小值 II → 搜索最小值
- No.187 旋转数组
- No.61 旋转链表
- No.151 翻转字符串里的单词 No.186 翻转字符串里的单词II
组合总和
- No.39 组合总和;No.40 组合总和II → 数字可重复/不可重复 → 求具体组合,dfs
- No.377 组合总和IV → 数字可重复 → 求个数,dp
- No.216 组合总和III → 和为 n 的 k 个数之和 → 求具体组合,dfs / 求个数,dp
覆盖子串
求字符串 s 中包含字符串 t 的最小子串
- No.76 最小覆盖子串:可以不按 t 的字符顺序出现 → t_idx == len(t) 时从后向前推
- No.727 最小窗口子序列:按 t 的字符顺序出现 → t_idx == len(t) 时从前向后推
买卖股票
- No.121 基础版,一次交易,动态规划
- No.122 基础版,无限次交易,贪心
- No.123 升级版,两次交易
- No.188 终极版,k 次交易
- 绝妙题解
硬币问题
- No.322 零钱兑换 → 凑成总金额所需的最少硬币个数
- No.518 零钱兑换II → 凑成总金额的组合数
打家劫舍
- No.198 & No.213 基础版,动态规划
- No.337 二叉树
众数问题——摩尔投票法
- No.169 多数元素 出现次数>n/2 次 → 只有1个
- No.229 求众数II 出现次数>n/3次 → 最多2个(2, 1, 0)
实现计算器问题
确定 stack 和 num 表示什么
- No.224 基本计算器:表达式由加减括号组成,每次遇到 ( ,把之前算好的数放进stack,遇到 ) 再放出来计算,num存储最终结果
- No.227 基本计算器II:表达式由加减乘除组成,stack里存所有数字,乘除法需要取出前一个数字一起计算
- [ ] No.772 基本计算器III:表达式由加减乘除括号组成
数组逆序对
- 剑指51. 逆序对
No.315 计算右侧小于当前元素的个数动态规划
No.62 不同路径
- No.64 最小路径和
- No.174 地下城游戏,逆推有点难想到
二维动态规划
- No.72 编辑距离
- No.97 交错字符串
- No.115 不同的子序列
- 剑指 Offer 60. n个骰子的点数
并查集 — Disjoint Set
- No.323 无向图中连通分量的数目
可用于检测图中是否有环:构建图,根据边的关系不断向图中合并节点,具体操作为找到两个顶点的根节点,让一个根节点指向另一个,即合并两个节点。如果合并的两个节点的根节点相同,说明图中有环。
1 | class Union(object): |
字典树/前缀树
- No.820 单词的压缩编码
Trie树,又叫字典树、前缀树(Prefix Tree)、单词查找树 或 键树,是一种多叉树结构。通常来说,一个字典树是用来存储字符串的。字典树的每一个节点代表一个字符串(前缀)。每一个节点会有多个子节点,通往不同子节点的路径上有着不同的字符。子节点代表的字符串是由节点本身的原始字符串,以及通往该子节点路径上所有的字符组成的。
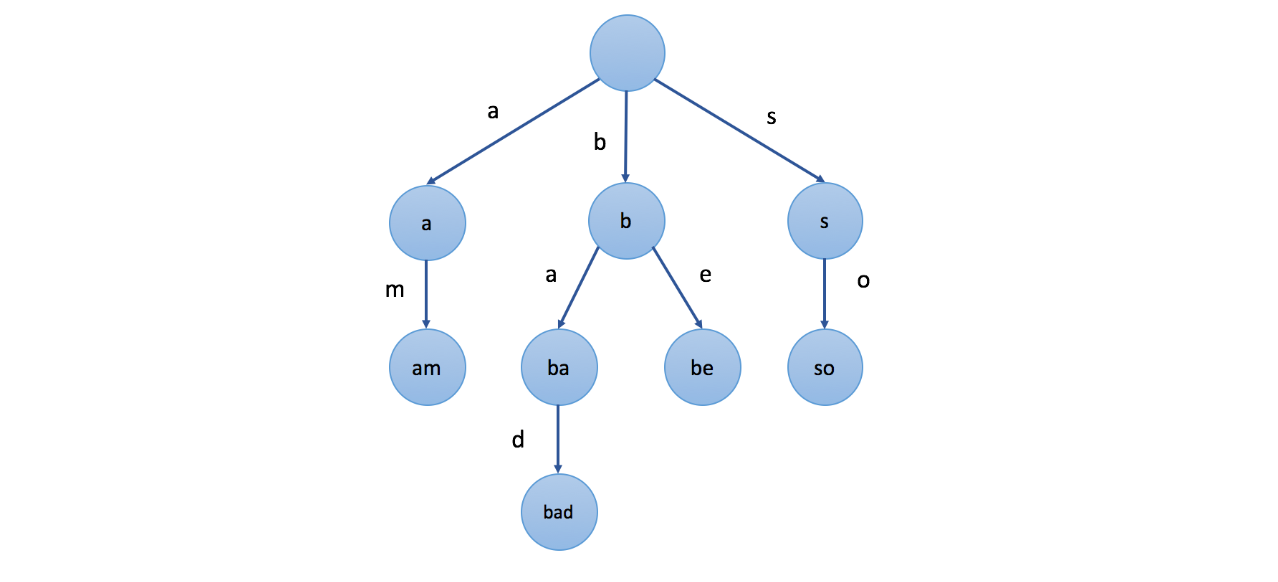
前缀树的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class TrieNode:
def __init__(self):
self.children = [None for _ in range(27)]
# 最后一个元素为1表示单词结束
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
cur = self.root
isNew = False
for letter in word:
idx = ord(letter)-ord('a')
if cur.children[idx] is None:
isNew = True # important!!!
cur.children[idx] = TrieNode()
cur = cur.children[idx]
cur.children[26] = True
return len(word) + 1 if isNew else 0
def search(self, word):
"""
Returns if the word is in the trie.
"""
cur = self.root
for letter in word:
idx = ord(letter)-ord('a')
if cur.children[idx] is None:
return False
cur = cur.children[idx]
# Doesn't end here
if cur.children[26]:
return True
else:
return False
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
cur = self.root
for letter in prefix:
idx = ord(letter)-ord('a')
if cur.children[idx] is None:
return False
cur = cur.children[idx]
return True
拓扑排序
- No.207 课程表;No.210 课程表II
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列,该序列必须满足下面两个条件:1)每个顶点出现且只出现一次;2)若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
以下图为例说明拓扑排序的算法:
1)从图中找到一个没有前驱(入度为0)的顶点;
2)删除该点和与其相邻的有向边;
3)重复以上步骤直到图为空或当前图中不存在没有前驱入度为0的顶点(该情况说明图中必然有环,此图不存在拓扑排序)
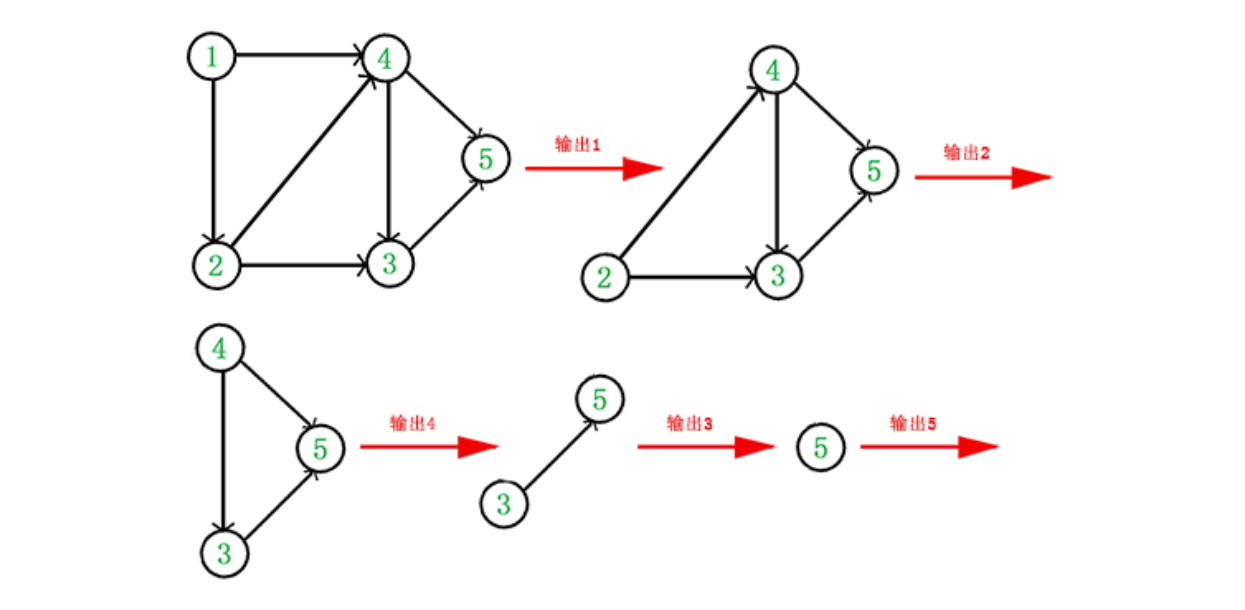
拓扑排序可以用BFS或DFS算法实现,其中BFS能够较为直观地知道该图是否为有向无环图以及输出拓扑排序结果,DFS需要定义flag数组,表示该节点是否被访问过、再次访问该节点时与前一次访问是同一个节点(有环)还是不同节点发起的DFS(正常拓扑排序),
TOP K问题
- No.324 摆动排序 (比较有趣但略复杂的题目)
在未排序的数组中找到第 k 个最大的元素。三种解法:数组排序,快速选择算法,Min-Heap小根堆。
数组排序
通过快排对数组排序后,下标为 n-k 的元素即为所求。时间复杂度最好O(nlogn),最差O(n^2),平均O(nlogn),空间复杂度O(logn)
Min-Heap小根堆
维护一个k元素的小根堆,遍历数组,当数组元素大于堆顶时,替换堆顶元素,最后的堆顶元素即为第k大的元素,时间复杂度O(nlogk),空间复杂度O(k)
快速选择算法
基于快速排序算法的优化,要找到第k大的元素,只要保证下标为 n-k 的元素,在它左边的元素都小于它,右边的元素都大于它。故可以用partition算法实现,只要得到的pivot下标为 n-k 即可。时间复杂度最好O(n),最差O(n^2),平均O(n)。
回溯法
一般可以分为主函数和core函数:主函数中检查无效输入,确定递归起点,当起点可以从任一点开始时,主函数加循环;core函数中注意判断终止递归的条件,注意勿重复访问,设置visited数组以免进入死循环,并注意core函数return前是否需要重置visited数组。
不需要重置visited数组,所有元素只访问一次:
- No.13 机器人的运动范围
包含多个答案,core函数返回前需要重置数组,以免影响其他结果:
No.17 电话号码的字母组合
No.46 全排列
No.79 单词搜索
No.131 分割回文串
写在最后
每一年都听到周围的人在说今年是xx岗最卷的一年,其实很多时候很多人都会有过动摇,想去最“不卷”的赛道,特别是做CV的人也都知道,僧多粥少,小厂也养不起一个人工智能研究院,仅剩的几个自然挤破了脑袋,所以很多人在秋招前转了开发。但是我就是不甘心吧,从大三开始学的东西让我一时间放弃着实难受,所以我有过压力大到下班骑车回来的路上哭成狗的时候,有一周内海投了八九家公司但是两周、三周过去了都没有被捞起的时候,甚至面试官很寻常的面试改期,在没有面试的那段时间成为压垮我的最后一根稻草。最后也在一次次的打击中不断摆正自己的心态,很想对当初崩溃的自己、对正在或者即将找工作的你们说:
要接受找实习和找正式工作的难度上的落差;
要相信自己,不被捞起、面试被拒,很多情况是这家公司HC不够或者根本没有匹配的岗位,而不是你不够优秀;
面试过程中的问题80%都不会,说明部门业务跟你所学差距很大,与其入职后高强度学习、工作,不如面试的时候就“拒”了它。
最后,祝我们都有美好的未来~祝各位心想事成~!